GLM-4.7 上线并开源。 新版本面向 Coding 场景强化了编码能力、长程任务规划与工具协同,并在多项主流公开基准测试中取得开源模型中的领先表现。
目前,GLM-4.7 已通过 BigModel.cn 提供 API ,并在 z.ai 全栈开发模式中上线 Skills 模块,支持多模态任务的统一规划与协作。
Coding 能力再提升
GLM-4.7 在编程、推理与智能体三个维度实现突破:
- 更强的编程能力:显著提升了模型在多语言编码和在终端智能体中的效果; GLM-4.7 现在可以在 Claude Code 、TRAE 、Kilo Code 、Cline 和 Roo Code 等编程框架中实现“先思考、再行动”的机制,在复杂任务上有更稳定的表现。
- 前端审美提升:GLM-4.7 在前端生成质量方面明显进步,能够生成观感更佳的网页、PPT 、海报。
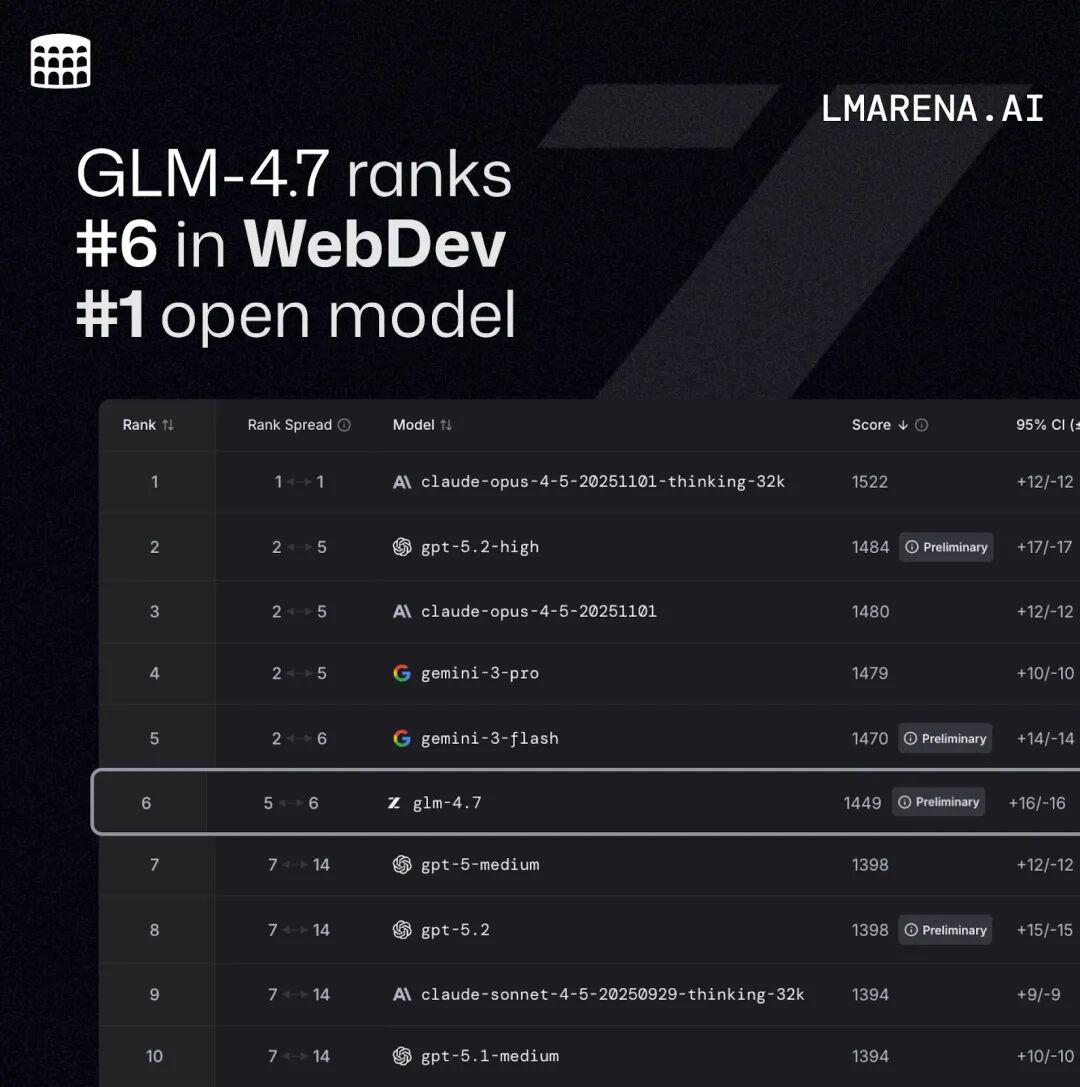
- 更强的工具调用能力:GLM-4.7 提升了工具调用能力,在 BrowseComp 网页任务评测中获得 67.5 分;在 τ²-Bench 交互式工具调用评测中实现 87.4 分的开源 SOTA ,超过 Claude Sonnet 4.5 。
- 推理能力提升:显著提升了数学和推理能力,在 HLE (“人类最后的考试”)基准测试中获得 42.8% 的成绩,较 GLM-4.6 提升 41%,超过 GPT-5.1 。
- 通用能力增强:GLM-4.7 对话更简洁智能且富有人情味,写作与角色扮演更具文采与沉浸感。
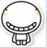
Code Arena:全球百万用户参与盲测的专业编码评估系统,GLM-4.7 位列开源第一、国产第一,超过 GPT-5.2 。
在主流基准测试表现中,GLM-4.7 的代码能力对齐 Claude Sonnet 4.5: 在 SWE-bench-Verified 获得 73.8% 的开源 SOTA 分数; 在 LiveCodeBench V6 达到 84.9% 的开源 SOTA 分数,超过 Claude Sonnet 4.5 ; SWE-bench Multilingual 达到 66.7%(提升 12.9%); Terminal Bench 2.0 达到 41%(提升 16.5%)。
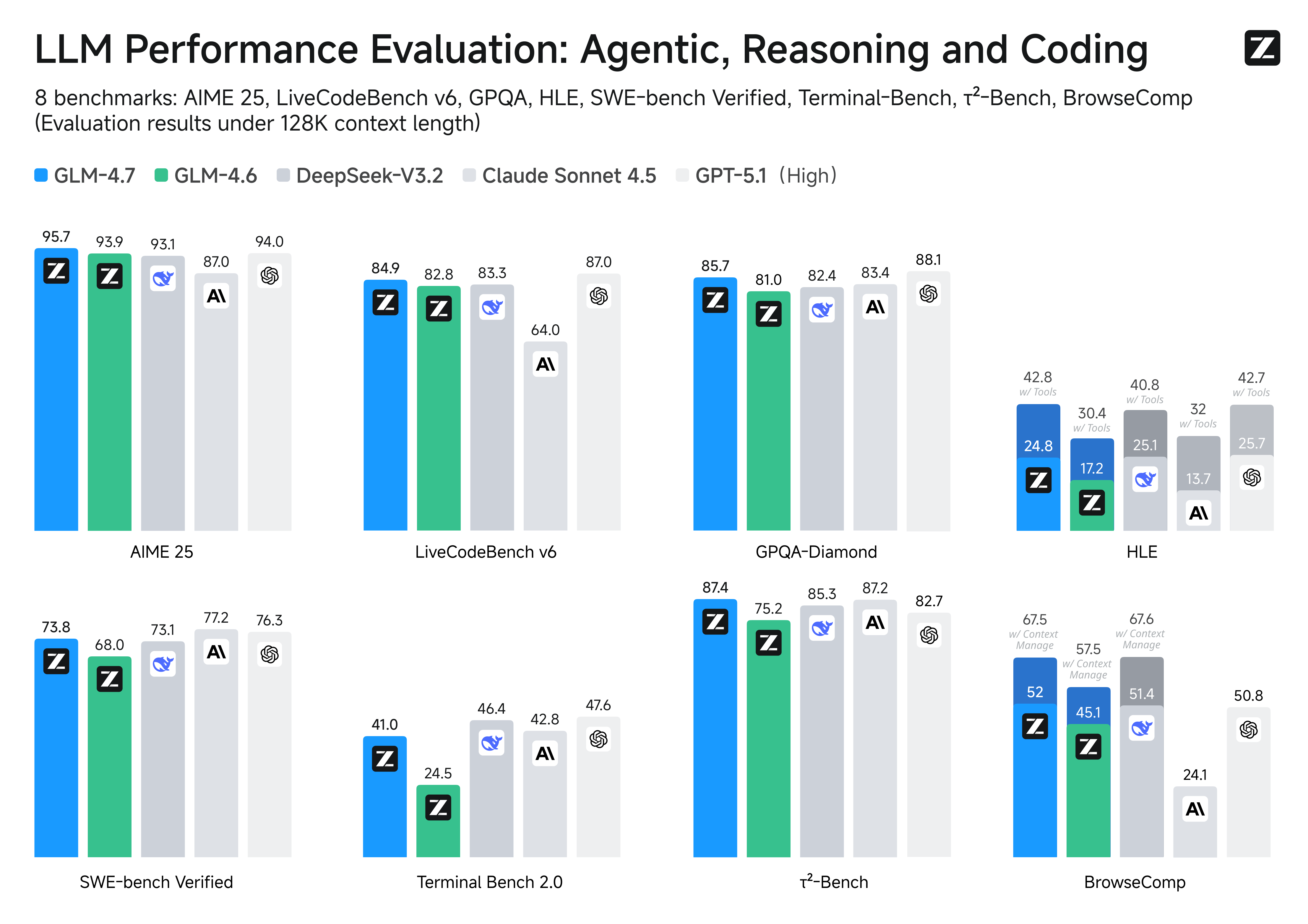
真实编程场景下的体感提升
在 Claude Code 环境中,我们对 100 个真实编程任务进行了测试,覆盖前端、后端与指令遵循等核心能力。结果显示,GLM-4.7 相较 GLM-4.6 在稳定性与可交付性上均有明显提升。
GLM Coding Plan
- Claude Code 全面支持思考模式,复杂任务连续推理与执行更稳定
- 针对编程工具里的 Skills / Subagent / Claude.md 等关键能力定向优化,工具调用成功率高、链路可靠
- Claude Code 中视觉理解能力开箱即用;内置搜索与网页读取,信息获取到代码落地一站闭环
- 架构设计与指令遵循更强,明显降低长上下文下的“幻觉式完成 / 跑偏”,交付质量更可控
作为本次升级的首个体验权益,所有购买套餐的用户将获得「体验卡」礼包,可邀请 3–7 位新用户免费体验 7 天套餐权益。
领取链接:[https://zhipuaishengchan.datasink.sensorsdata.cn/t/kc]